지금까지 CS를 공부하면서 내가 생각한 렌더링 과정
사용자가 주소창에 주소를 입력 → 브라우저가 서버에 html 요청 → 서버가 html 파일을 응답 → 브라우저가 html을 파싱→ DOM 트리구조로 그림 → 각각 노드에 맞는 js나 css 해 → 짜잔
이런 과정인 줄 알았는데 내가 생각한 과정이 맞는지, 좀 더 개발자다운 용어는 무엇인지 정리해보려고 한다.

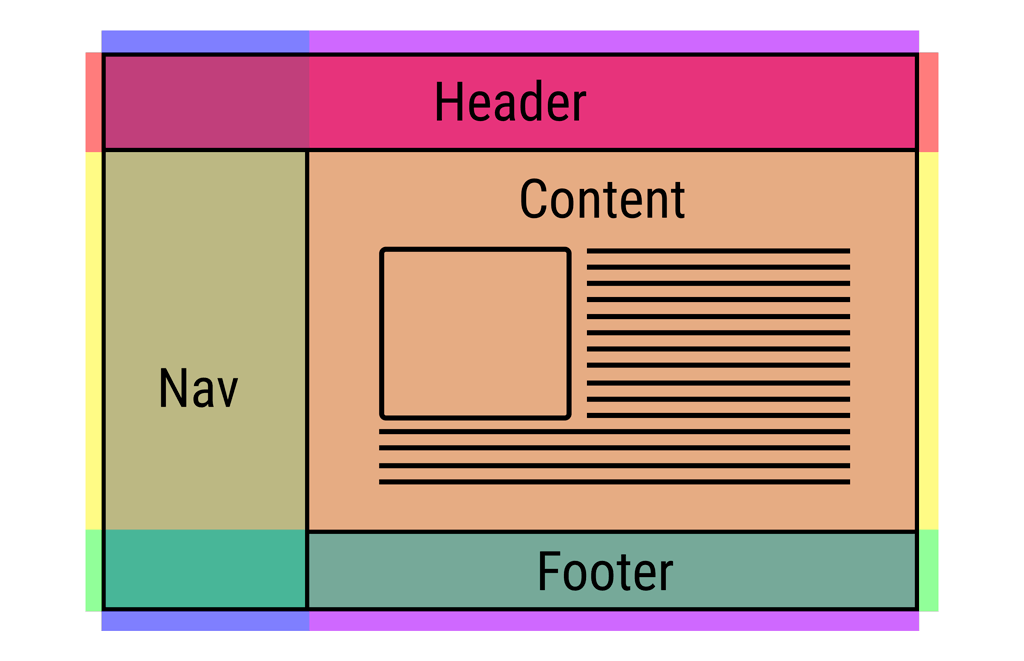
브라우저
웹 서버와 통신하여 인터넷 사이트 및 다양한 컨텐츠를 볼 수 있도록 지원해주는 소프트웨어 프로그램. 브라우저의 주요 기능은 사용자가 선택한 자원을 서버에 요청하고 브라우저에 표시하는 것.
브라우저 종류는 다양하지만 최근은 구글 크롬, 사파리, 엣지, 파이어폭스, 오페라 순으로 많이 사용하고 이 중 크롬은 압도적 1등이다.
웹 브라우저 시장 점유율
브라우저 기본 구조
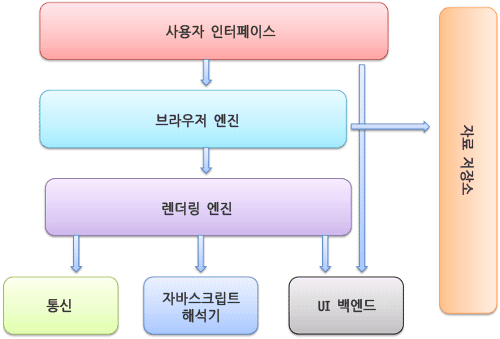
- 사용자 인터페이스, User Interface / UI
- 요청한 페이지를 보여주는 창을 제외한 나머지 모든 부분
- 주소 표시줄, 이전/다음 버튼, 북마크 메뉴 등

- 브라우저 엔진 / 레이아웃 엔진
- 사용자 인터페이스와 렌더링 엔진 사이의 동작 제어
- UI를 그리는 UI 스레드, 네트워크 통신을 위한 네트워크 스레드, 파일에 접근하기 위한 스토리지 스레드 등이 존재
- 렌더링 엔진
- HTML, CSS 등 요청한 콘텐츠를 파싱하여 응답받은 내용을 화면에 나타내는 일 수행
- 브라우저 엔진과 밀접히 관련된 엔진. 웹 페이지가 표시되는 모든 영역 제어
- 통신
- HTTP 요청과 같은 네트워크 호출에 사용
- 플랫폼 독립적인 인터페이스로 각 플랫폼 하부에서 실행
- 자바스크립트 해석기, JS Interpreter / 자바스크립트 엔진
- 스크립트를 파싱할 때 사용하는 JS 엔진
- 자바스크립트 코드를 해석하고 실행
- HTML 파싱 중 script 태그를 만나면, JS 엔진이 제어 권한을 넘겨 받아 동기적으로 진행.
- UI 백엔드
- 기본 위젯을 그릴 때 이용
- 플랫폼에서 명시하지 않은 일반적인 인터페이스
- OS의 유저 인터페이스 메서드를 사용해 창이나 콤보박스, 체크박스 등의 기본적인 위젯
- 자료 저장소 / 데이터 저장소
- 자료 저장소
- 쿠키나 localStorage 같이 로컬에 저장되어 좀 더 오래 유지되어야 하는 데이터들을 보관할 수 있도록 지원하는 영역
크롬은 각 탭마다 별도의 렌더링 엔진 인스턴스를 유지한다. 각 탭은 독립된 프로세스로 처리
높은 보안성과 더 좋은 사용성을 제공
DOM
문서 객체 모델. 쉽게 말해 객체로 표현된 HTML 문서
DOM 트리
브라우저는 HTML 텍스트 문서를 바로 읽을 수 없음.
이를 객체의 형태로 바꾸어 브라우저가 읽을 수 있는 트리 구조로 변환.
DOM 트리는 최상위 노드인 ‘문서 노드’부터 아래 방향으로 순차적 탐색.
자바스크립트를 통해 HTML 문서에 접근할 때, 혹은 페이지를 조작하는 이벤트가 발생할 때 이러한 과정이 발생.
그리고 DOM 트리는 생성과정에서 브라우저는 HTML 문서에 있는 에러들을 자동으로 처리
브라우저 주소창에 URL 검색
주소 검색 창에 www.naver.com 을 치고 Enter을 눌렀을 때!!!
→ 3단계로 구분 가능

1. 입력한 텍스트 정보 확인
대부분 브라우저는 주소창과 검색엔진과 같이 사용.
그래서 내가 입력한 텍스트가 검색어 인지, URL 인지 확인. → 이 작업은 브라우저 엔진의 UI 스레드
- 텍스트가 검색어
브라우저는 검색 엔진의 URL에 검색어를 포함한 주소로 페이지 이동 - 텍스트가 URL
브라우저 엔진(→ 네트워크 스레드)에서 네트워크 호출 수행
위와 같이 www.naver.com 을 입력한 경우 URL 이기 때문에 네트워크 호출을 수행
2. 네트워크 호출
쉽게 표현하자면 컴퓨터 세상에서 집 주소의 개념인 IP 주소를 찾는 것.
브라우저가 사용자에게 네이버 사이트 화면을 보여주려면 네이버 페이지의 HTML, CSS, JavaScript, 이미지, 글꼴 등 다양한 리소스를 서버에서 받아와야함.
하지만 이 데이터들은 네이버 서버 컴퓨터에만 존재.
브라우저는 네이버 서버와의 네트워크 통신을 통해 데이터들을 요쳥해야함.
데이터를 요청하기 위해 브라우저는 네이버 서버가 있는 컴퓨터의 집 주소인 IP 주소부터 파악할 필요가 있음.
네이버 서버의 IP 주소 찾는 방법
클라이언트는 DNS 서버에 검색하기 전에 캐싱된 DNS 기록들을 먼저 확인
해당 도메인 네임 (naver.com)에 대응하는 IP 주소(125.209.222.142)가 있는지 확인
- 있으면 해당하는 IP주소를 요청하지 않고 캐싱된 IP 주소 반환
- 없으면 DNS server (= Name Server)에 ‘네이버의 IP 주소를 알려주세요’ 라는 요청
도메인 네임 → www.naver.com 에서 naver.com 해당하는 부분
인터넷은 컴퓨터의 주소인 IP 주소를 기반으로 동작하지만 우리가 인터넷을 사용할 때 IP 주소 대신 사용하기 쉽도록 문자로 이루어진 도메인 네임을 사용.
그래서 도메인 주소를 IP 주소로 변환해주는 DNS(Domain Name Server)가 반드시 필요.
DNS를 운영하는 장치를 DNS Server 또는 Name Server 라고 함.
DNS Server → 도메인 주소에 대응하는 IP 주소를 찾아주는 역할 수행
네이버 서버와 통신하여 필요한 데이터 얻는 과정
이제 브라우저가 네이버 IP 주소를 알게 되었고 네이버 서버와 통신할 수 있게 되었다.
클라이언트의 브라우저는 네이버 서버에 데이터를 요청하는 HTTP Request 를 보내고
HTTP Request를 받은네이버 서버는 클라이언트가 요청한 문서를 찾아 읽고 이를 바이트 형태 (1 또는 0으로 이루어짐) 로 변환하여, 클라이언트로 HTTP Response 를 보낸다.
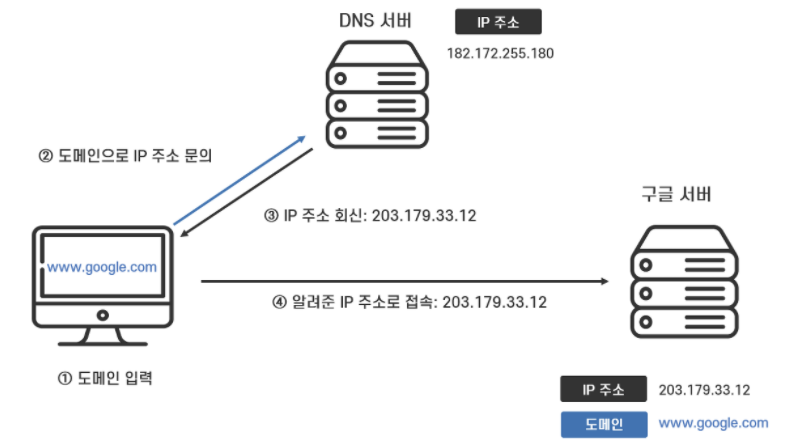
여기까지가 데이터를 불러오는 과정.
이제는 받아온 데이터를 그려야함.
렌더링
받아온 데이터의 내용대로 화며에 그리는 것을 렌더링.
렌더링에 필요한 것은 HTML과 CSS 문서.
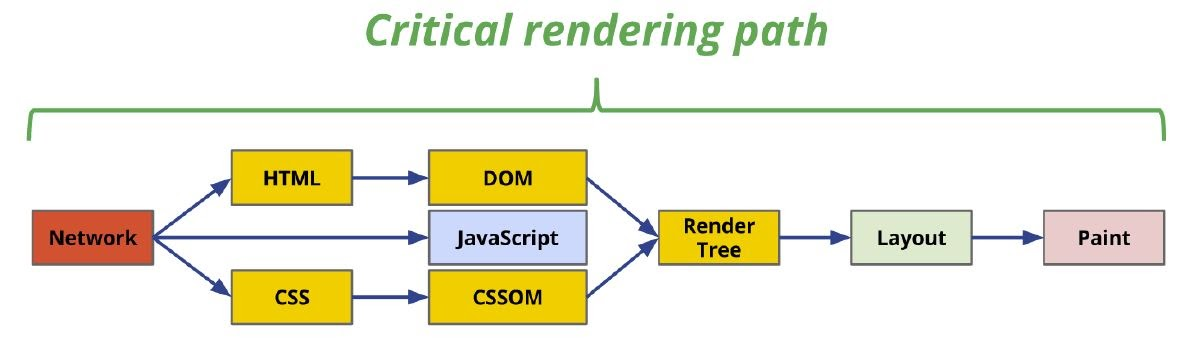
웹 브라우저에 출력되는 단계를 Critical Rendering Path 라고 함.
브라우저 엔진-네트워크 스레드은 네이버 서버로부터 응답받은 데이터에 악성 바이러스가 있는지 우선 검사 실시.
→ 이 데이터는 바이트 형태의 텍스트 문서이므로 브라우저 엔진이 읽을 수 없음
→ 브라우저 엔진-UI 스레드은 렌더링 엔진에게 해당 데이터를 해석하고 웹 페이지를 화면에 띄울 것을 요청
→ 요청 받은 렌더링 엔진은 받은 데이터를 바탕으로 렌더링 프로세스를 수행하고 이 과정이 끝나면 브라우저 엔진에게 작업 완료를 알림.
→ 네이버 페이지 짜잔!
렌더링 엔진
브라우저 엔진으로부터 요청받은 내용을 브라우저 화면에 표시해주는 역할.
브라우저마다 사용하는 렌더링 엔진이 각각 다름.
- 크롬 → 웹킷(Webkit) 엔진을 사용했다가, 웹킷을 Fork 하여 자체적으로 구현한 블링크(Blink) 엔진 사용
- 파이어폭스 → 모질라에서 직접 만든 게코(Gecko) 엔진 사용
- 사파리 → 웹킷(Webkit) 엔진 사용
CSS 접두어에 -webkit-, -moz-, -ms- 등을 같이 사용한다.
크롬의 Webkit 엔진을 보고 깨달았다…. 아마 브라우저마다 모든 렌더링 엔진이 달라서 CSS를 같은 방식으로 해석하지 못하니까, 각 브라우저 환경에 맞게 접두어를 사용해 해당 브라우저의 렌더링 엔진에 맞게 CSS를 해석하도록 사용했던 거라고 다시 한번 이해하게되었다.
웹킷(+Blink) 렌더링 프로세스
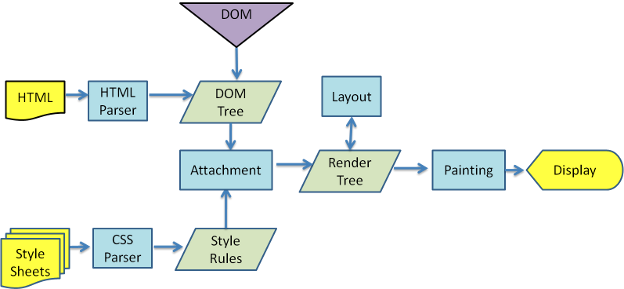
게코 렌더링 프로세스
렌더링 프로세스
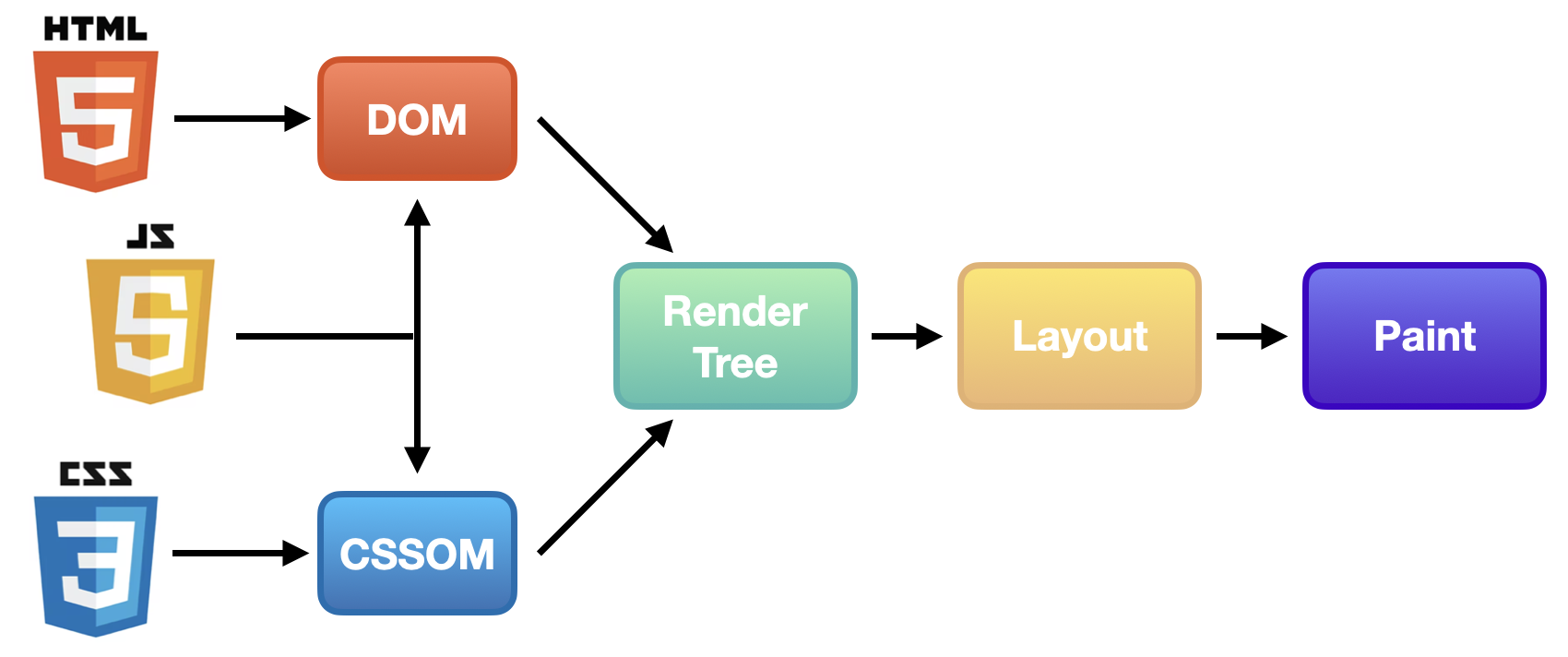
렌더링 과정은 총 4단계
- 파싱
1-1. HTML 문서 파싱 → DOM 트리 생성
1-2. CSS 문서 파싱 → CSSOM 트리 생성 - Render Tree 구축
- Layout (Render Tree 배치)
- Paint (Render Tree 그리기)
1. 파싱
렌더링 과정 중 가장 중요한 것.
브라우저는 HTML, CSS 등의 단순한 텍스트 문서를 이해할 수 없기 때문에 브라우저가 읽을 수 있도록 변환하는 과정.
즉, 서버로부터 전송받은 문서의 문자열을 브라우저가 이해할 수 있는 구조로 변환하는 과정
1-1. HTML 파싱
렌더링 엔진이 HTML 문서를 수신 받으면, HTML 파서는 이를 위에서부터 읽어 내려가며 파싱 진행.
DOM 트리 생성
HTML 파싱 과정
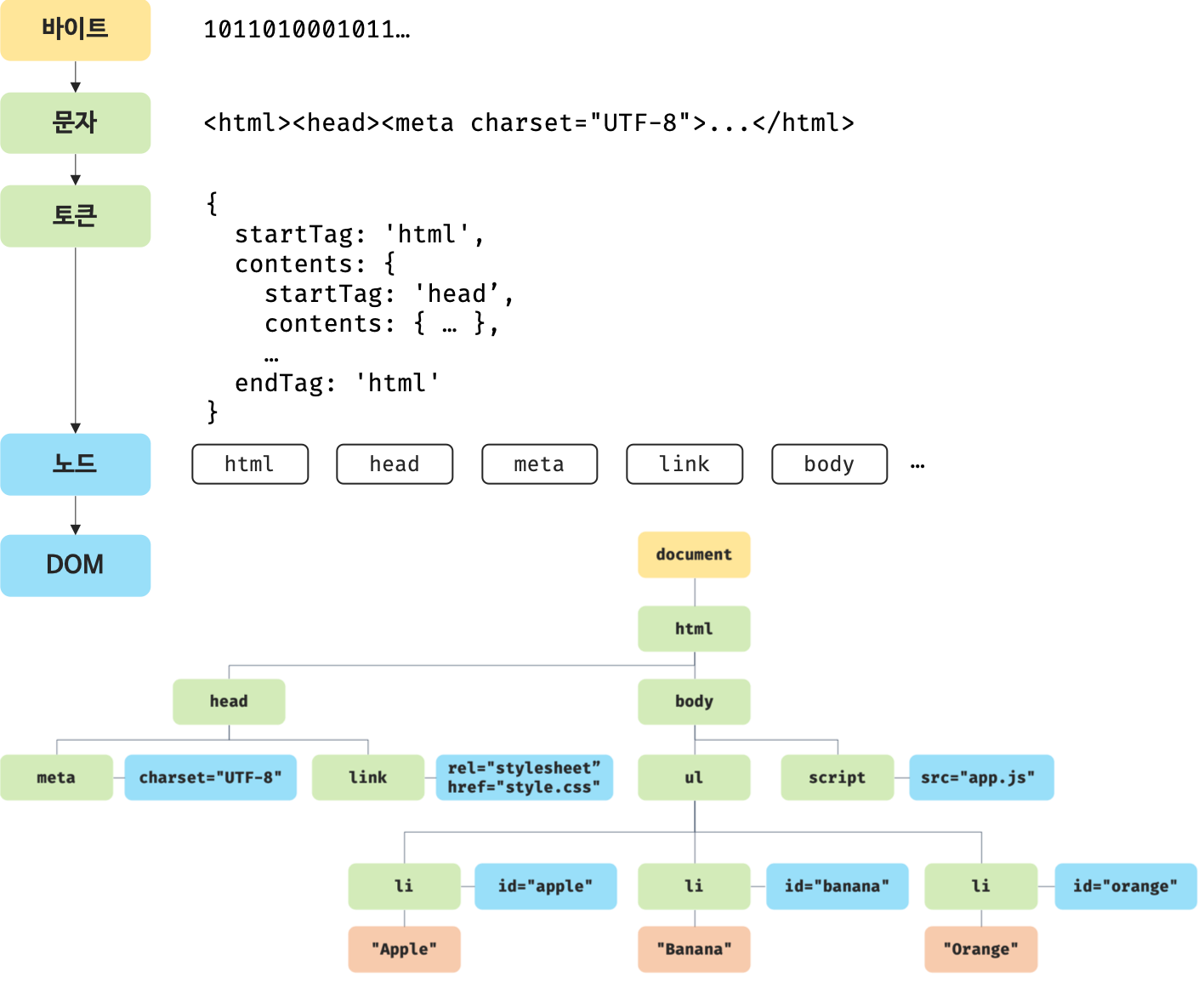
- 서버에서 바이트 형태의 HTML 문서 응답
- 저장된 인코딩 방식 (UTF-8)에 따라 이를 문자열로 반환
1
<meta charset="UTF-8"> - 변환된 문자열을 토큰으로 분해
- 토큰을 내용에 따라 객체(노드) 로 변환
- 객체를 트리 구조로 구성하여 DOM 생성
렌더링 엔진은 사용자의 만족도를 높이기 위해 HTML 문서가 모두 파싱될 때까지 기다리지 않고 파싱 이후의 과정인 배치와 그리기를 미리 진행.
1-2. CSS 파싱
CSS 파서는 서버에 수신받은 CSS 문서를 파싱하여 CSSOM 트리를 생성
HTML 파싱 중 CSS 문서를 가져오는 <link> 나 <style> 태그를 만나면 렌더링 엔진은 DOM 생성을 잠시 중단하고 해당 CSS의 파싱 과정이 시작.
CSS 파싱 과정
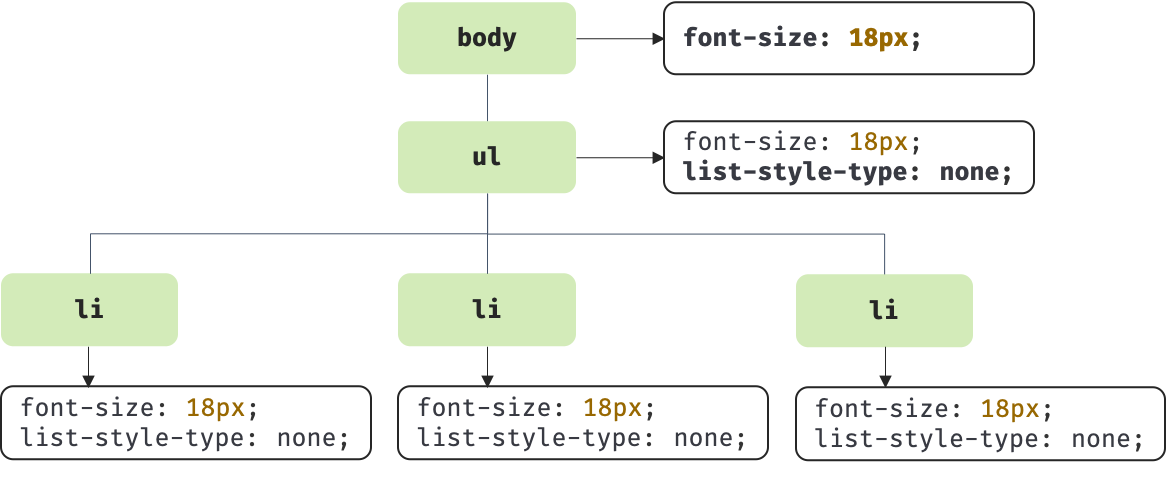
CSS 파싱 과정은 기본적으로 HTML 파싱 과정과 동일
JS는 <script> 태그를 사용해서 파일이나 링크를 <body> 태그 안에 넣을 수 있는데, CSS는 <head> 태그 안에 <link>태그와 <style> 태그를 넣는다. 이게 다 이유가 있었던 것이다.
CSS는 렌더링 할 때 반드시 필요한 리소스이기 때문에 브라우저는 빠르게 CSS를 다운로드 하는 것이 좋아서 <head> 태그 안에서 정의하여 빠르게 리소스 받을 수 있게 하기 위해서
1-3. JS 파싱
HTML 파싱 중 <script>태그를 만나면 렌더링 엔진은 DOM 생성을 잠시 중단하고 JS 파싱 진행.
JS 파싱이 끝나면 렌더링 엔진은 다시 HTML 문서를 파싱
<script> 태그가 <body> 태그 중간에 작성될 경우, HTML 파싱을 하는 도중 갑자기 JS 파일을 읽게 되므로 오류 발생 위험이 있음. 그래서 <script> 태그는 <body> 최하단에 위치
혹은 <script>에 defer 라는 속성을 부여.
Render Tree
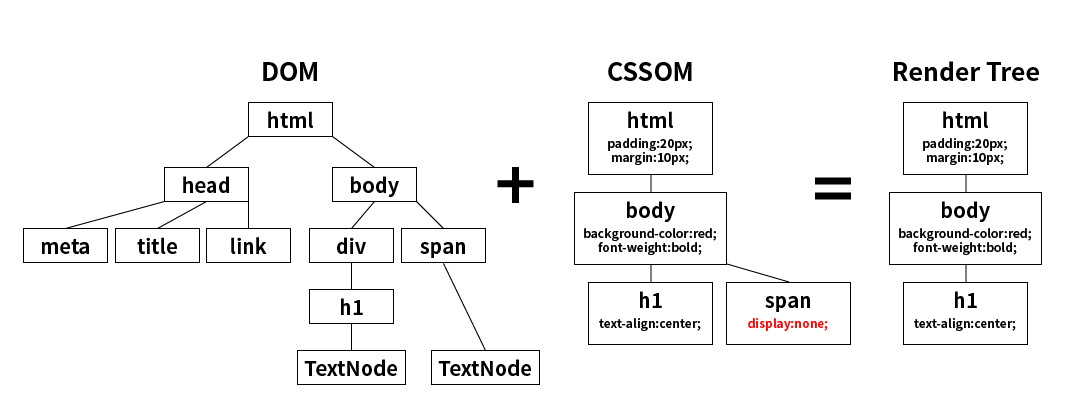
파싱하여 만든 DOM 트리와 CSSOM 트리를 서로 결합하여 렌더 트리 (Render Tree) 생성
실제 화면에 표현되는 노드들로만 구성된 트리. (화면상 공간을 차지하느냐)
렌더 트리 생성 과정
- 태그와 태그를 처리하며 **렌더 트리 루트** 구성
- DOM의 최상위 노드부터 순회하면서 화면에 보여지지 않는 노드를 렌더 트리의 구성에서 제외
- 화면에 보여지는 나머지 노드에 CSSOM 규칙을 찾아 일치하는 스타일 적용.
레이아웃
렌더트리의 노드를 화면에 배치하는 과정.
렌더 트리 생성이 끝나면 웹페이지 화면 안에서 렌더트리에 있는 각 노드의 위치와 크기, 너비, 높이 등을 계산하고 화면에 배치하는 레이아웃 과정이 실행
이 과정에서 뷰포트 내에서 생성된 render tree의 각 노드들이 스크린 상의 어느 공간에 위치해야할지 결정됨.
이때 모든 상대적인 값 (rem, vw 등)이 절대단위인 px로 변환
레이아웃 구분 방법
- 글로벌 레이아웃
- 전체의 배치과정이 필요한 경우
- 맨 처음에 배치되거나 font와 같은 전역 스타일이 변경될 경우, 창이 resize되는 경우 전체적으로 레이아웃 과정이 일어남.
- 초기 배치 이후 요소의 크기나 위치가 변할 때 레이아웃이 다시 일어나는 것 → 리플로우(Reflow)
- 로컬 레이아웃
- 일부의 배치과정만 변경하면 되는 경우
- 초기 배치 이후 일부 DOM 노드에 변경이 생기는 것 처럼, 특정 부분만 재배치가 필요한 경우 발생
- 화면의 일부만 바뀌어도 전체 배치를 새로하는 것은 너무 비효율적
페인트

레이아웃 과정에서 계산된 정보들을 바탕으로 각 노드들을 화면에 그려주는 과정
렌더 트리의 각 노드를 화면의 실제 픽셀로 변환해주는 작업. 이 과정을 레스터화 (Rasterizing)라고 함.
페이트 과정 중 화면의 특정 위치에 여러 개의 노드가 함께 그려지는 경우, 여러 레이어를 만들고 다시 합성하는 방식으로 작업.
페인트 과정이 끝나면 브라우저 화면에 네이버 페이지가 보여진다.
브라우저에 특정 변경이 생긴다면 이를 화면에 다시 그려주어야 하는데 이 과정을 리페인트 (Repaint) 라고 함.
기본적으로 리플로우가 발생하면 리페인트도 함께 발생.
Reflow vs Repaint
위 4단계 과정을 모두 마치면 브라우저에 화면이 그려짐.
하지만 특정 액션이나 이벤트에 따라 HTML 요소의 크기나 위치 등의 레이아웃 수치가 변하면
해당 요소의 영향을 받는 자식 노드나 부모 노드들을 포함하여 레이아웃 (Reflow) 과정을 다시 수행.
이럴경우 각 요소들의 크기와 위치를 다시 계산하게 되는데 이 과정을 Reflow
Relfow 된 렌더 트리를 다시 화면에 그려주는 과정을 Repaint
Reflow가 일어나는 경우
- 페이지 초기 렌더링 시 (최초 레이아웃 과정)
- 브라우저 리사이징 시 (Viewport 크기 변경)
- 노드 추가 또는 제거
- DOM 노드의 위치 변경
- DOM 노드의 크기 변경
- 요소의 위치, 크기 변경
- 폰트 변경과 이미지 크기 변경
Repaint
- Reflow가 발생하지 않아도 background-color 나 opacity 같이 레이아웃에 영향을 주지 않는 스타일 속성이 변했을 때 Reflow 없이 Repaint만 일어남.
Reflow → 화면에 변화가 있을 때 화면을 다시 그리는 과정.
Repaint → 뷰포트 내에서 렌더 트리의 노드의 정확한 위치와 크기를 계산하는 과정.
Reflow 경우 → 화면이 변경되는 모든 경우
Repaint 경우 → 화면의 구조가 바뀌었을 경우
렌더링 최적화
- Reflow 최소화
- Reflow가 발생하면 필연적으로 Repaint가 일어나기 때문에 렌더링 최적화에 좋지않음.
따라서 Reflow가 발생하는 속성보다 Repaint만 발생하는 속성을 사용하는 것이 좋음.
- Reflow가 발생하면 필연적으로 Repaint가 일어나기 때문에 렌더링 최적화에 좋지않음.
- CSS 문서와 JS 문서로 인한 비효율 줄이기
- CSS
- <link>, <style> 태그 <head> 태그 안에 배치
- 미디어 유형과 미디어 쿼리 이용
- JS
- <script> 태그를 <body> 최하단에 위치
- async 속성을 <script> 태그에 부여
- defer 속성을 <script> 태그에 부여
- CSS
- 영향을 주는 노드 최소
JavaScript와 CSS를 조합해 애니메이션이나 레이아웃 변화가 많은 요소의 경우 position 을 absolute 또는 fixed를 사용하면 영향을 받는 주변 노드들을 줄일 수 있음.
fixed와 같이 영향을 받는 노드가 전혀 없는 경우 Reflow과정이 전혀 필요없어지기 때문에 Repaint연산비용만 들게 되어 효율적
평가
렌더링 최적화를 알아보다가 렌더링을 최적화 시킬 수 있는 방법을 알려면 브라우저가 렌더링 되는 과정부터 알아야겠다고 생각이 들었다.